📝📝:大型語言模型如何應用在神經科學的研究?|倫敦大學學院:經過訓練後的模型,準確率遠高過人類專家


本文翻譯自《Nature Human Behaviour》的研究《Large language models surpass human experts in predicting neuroscience results》由倫敦大學學院(University College London)實驗心理學(Department of Experimental Psychology)的研究團隊 Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun 等人所主持的研究項目。
科學發展中的挑戰
隨著科學文獻的指數增長,研究人員面臨巨大的資訊整合挑戰。
在神經科學(neuroscience)等跨學科領域,研究成果往往分散於大量資料中,而每篇文章的研究方法和結論可能不一致,甚至存在噪音。這對於人類專家來說,是一個超出資訊處理能力的難題。
為解決這些問題,研究者開始利用大規模語言模型(LLMs)來輔助科學預測和發現。這些模型具備從海量數據中提取模式並預測新結果的能力,或能為未來的科學探索提供重要助力。
---
.
研究方法:打造神經科學的前瞻性基準
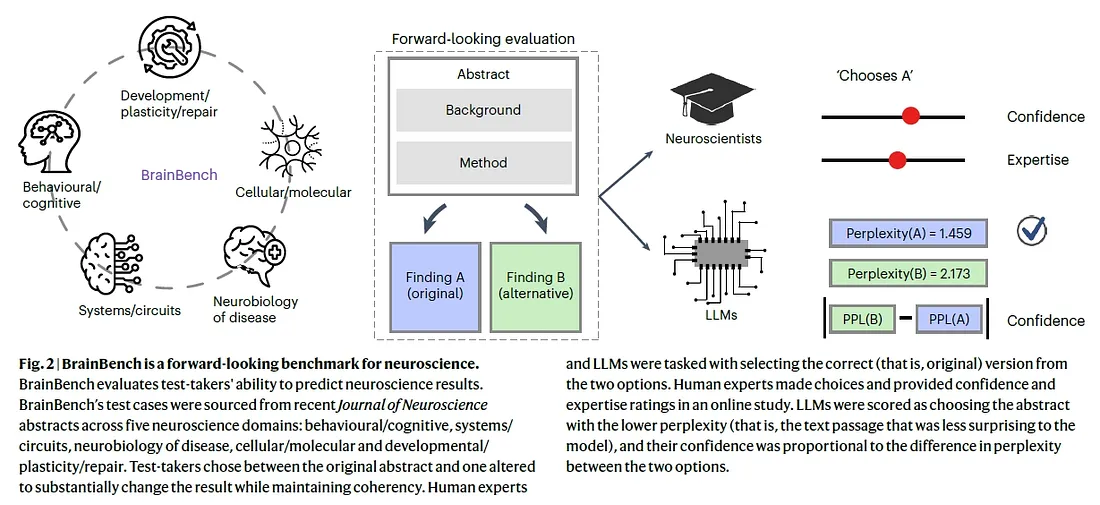
為了檢驗LLMs在科學預測上的能力,研究者開發了一套名為 BrainBench 的評估系統。
該系統專注於測試模型是否能準確預測神經科學研究結果,並將其表現與人類專家進行對比。BrainBench的核心任務是提供一個修訂版與原始研究摘要,讓測試者選擇哪一個更可能反映真實的研究結果。
此基準主要測試模型在五個神經科學領域中的表現:
- 行為與認知(Behavioral/Cognitive)
- 系統與迴路(Systems/Circuits)
- 疾病神經生物學(Neurobiology of Disease)
- 細胞與分子(Cellular/Molecular)
- 發展與可塑性(Development/Plasticity/Repair)

---
.
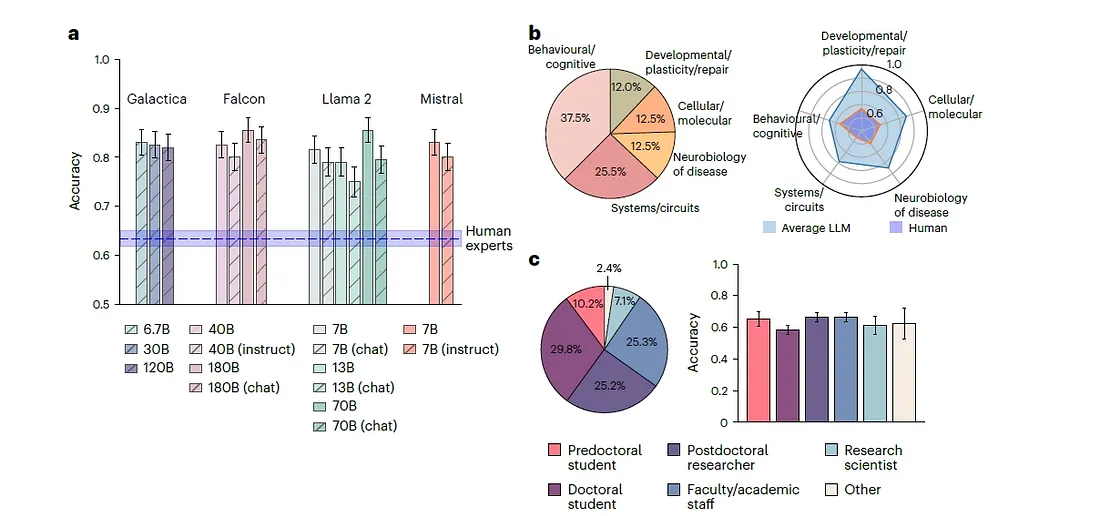
關鍵結果:LLMs 的超越性表現
在測試中,大規模語言模型的平均正確率達到 81.4%,明顯高於人類專家的 63.4%。更重要的是,經過神經科學專業調適的模型(例如 BrainGPT),表現進一步提升。
以下為 LLMs 表現優越的原因分析:
.資訊整合能力強
.預測準確性與信心一致
.未受數據記憶限制

模型優化:從一般到專業
為了提升LLMs在神經科學的應用能力,研究者採用了 LoRA(低秩適應) 方法,進行專業知識調適。通過在數百萬字的神經科學文獻上進行微調,研究團隊將LLMs轉化為更加專業化的工具 — — BrainGPT。
調適後模型的主要進步:
.在 BrainBench 測試中的正確率提升了約 3%。
.模型在理解專業術語與方法學上的能力顯著增強。
---
.
挑戰與展望
儘管LLMs展現出強大的預測能力,研究者仍需考量潛在風險:
.過度依賴模型
.科學倫理與透明性
展望未來,LLMs可以:
作為科學研究的輔助工具,指導實驗設計。
成為探索未知領域的重要夥伴,幫助解答跨學科問題。
本研究的突破在於首次系統性地驗證LLMs在神經科學領域的前瞻性應用能力。隨著技術的進步,我們可以期待這些模型成為推動科學發現的新引擎,為知識密集型領域帶來前所未有的效率與可能性。